
Ataki przeciążeniowe potrafią sparaliżować sklep internetowy, panel klienta albo API szybciej, niż zespół zdąży zareagować. W tym tekście wyjaśniam, jak działa atak DDoS, jakie ma warianty, po czym go rozpoznać i jak zbudować obronę, która nie rozsypie się przy pierwszym większym skoku ruchu. Skupię się na praktyce: na sygnałach ostrzegawczych, typowych błędach i działaniach, które realnie skracają czas przestoju.
Najważniejsze fakty o atakach przeciążeniowych w jednym miejscu
- To nie jest klasyczne włamanie, tylko zalew ruchu mający odciąć dostęp legalnym użytkownikom.
- Najczęściej źródłem jest botnet, czyli sieć przejętych urządzeń rozproszonych po wielu lokalizacjach.
- Najgroźniejsze są dziś ataki wielowarstwowe, łączące przeciążenie sieci z zalewem zapytań do aplikacji.
- Skuteczna obrona zaczyna się od architektury: CDN, WAF, rate limiting, dobre DNS i plan reakcji.
- Sama skala ruchu nie jest jedynym problemem; duże ryzyko stanowi to, że atak bywa podobny do prawdziwego wzrostu zainteresowania.
Czym jest rozproszona odmowa usługi i co faktycznie blokuje
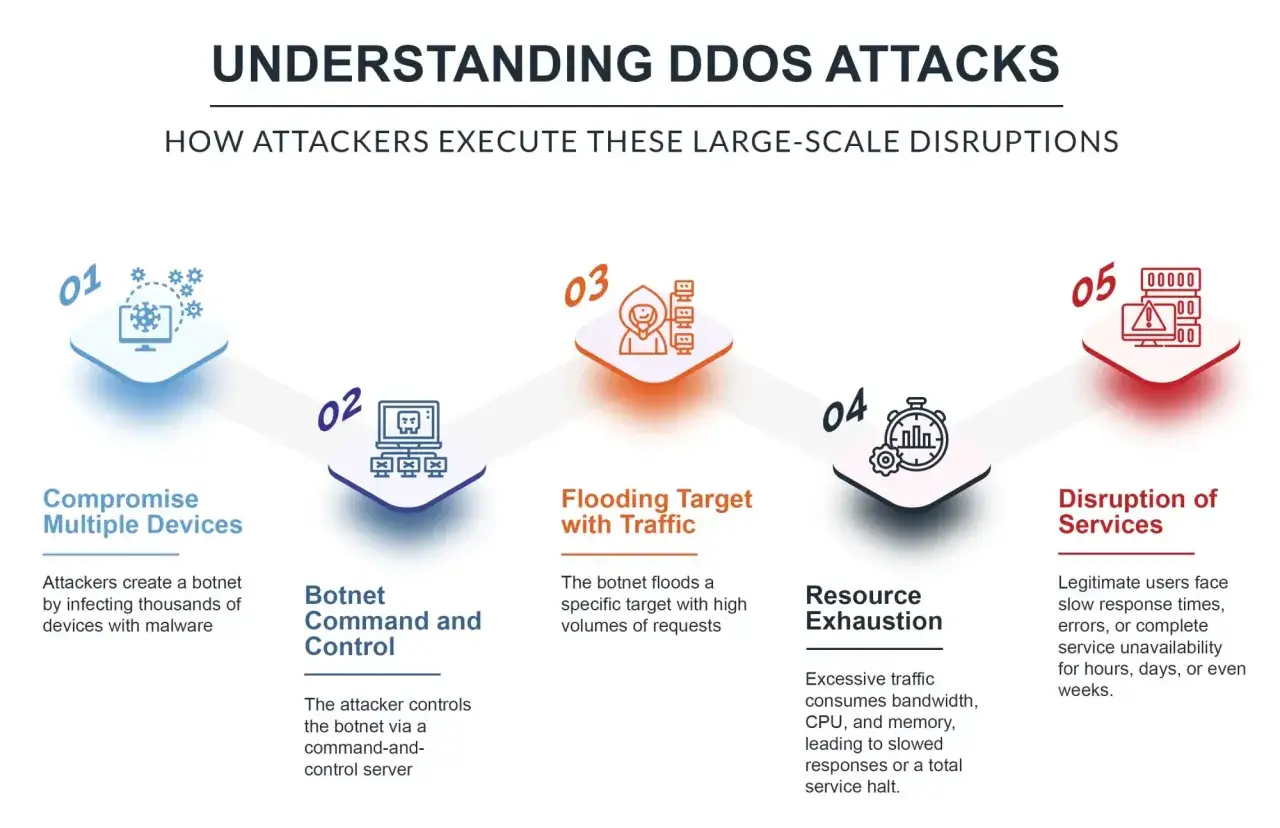
To nie jest klasyczne włamanie, w którym napastnik próbuje dostać się do danych. Celem jest dostępność: serwis ma przestać odpowiadać użytkownikom, bo zostaje zalany ruchem albo zapytaniami, których nie jest w stanie obsłużyć. Ja zwykle tłumaczę to prosto: jeśli normalnie aplikacja obsługuje 10 tysięcy żądań na minutę, a nagle dostaje ich dziesięć razy więcej z tysięcy rozproszonych źródeł, zaczynają pękać kolejno łącze, load balancer, serwer aplikacyjny, baza albo DNS.
Źródłem ruchu bardzo często jest botnet, czyli sieć przejętych urządzeń: komputerów, kamer, routerów czy serwerów VPS. Rozproszenie ma znaczenie, bo utrudnia filtrowanie na podstawie jednego IP, jednego kraju albo jednego wzorca zachowania. To właśnie dlatego takie incydenty potrafią wyglądać jak nagły sukces marketingowy, a w praktyce są próbą odcięcia usług od realnych klientów.
Żeby zrozumieć, dlaczego ten mechanizm bywa tak skuteczny, trzeba zobaczyć, co dzieje się w ruchu sieciowym i gdzie obrona najczęściej się załamuje.
Jak działa atak DDoS od strony technicznej
Na poziomie technicznym napastnik nie musi wywołać jednego gigantycznego strzału. Częściej wysyła wiele mniejszych fal, które razem przekraczają próg wydolności systemu. Czasem chodzi o przepchnięcie łącza, czasem o wyczerpanie stanów sesji, a czasem o to, by kosztowne operacje aplikacyjne zjadały CPU i pamięć, zanim system zdąży odpowiedzieć legalnym klientom.
Najtrudniejszy element obrony polega na odróżnieniu złego ruchu od dobrego. Cloud lub CDN może zobaczyć miliony poprawnych zapytań, ale jeśli pochodzą z nietypowych wzorców, z powtarzalnych fingerprintów albo uderzają w jeden kosztowny endpoint, trzeba je odsiać bez zatrzymywania prawdziwych użytkowników. Microsoft Learn podkreśla przy ochronie sieciowej, że warstwa L3/L4 nie zastępuje WAF-u: pierwsza pomaga przy zalewie sieciowym, druga przy atakach aplikacyjnych, takich jak flood HTTP.
W praktyce najlepsze rozwiązania robią trzy rzeczy jednocześnie: obserwują ruch, automatycznie ograniczają podejrzane połączenia i przepuszczają resztę możliwie najkrótszą drogą do usługi. To prowadzi do pytania, jakie odmiany takiego przeciążenia spotyka się najczęściej i dlaczego nie wszystkie wyglądają tak samo.
Najczęstsze warianty i czym różnią się w praktyce
W tej części najbardziej przydaje się porównanie, bo z zewnątrz wiele ataków wygląda podobnie, a obrony wymagają zupełnie innej. Ja zwykle patrzę na to przez pryzmat warstwy, która dostaje pierwszy cios.
| Wariant | Co przeciąża | Jak zwykle wygląda | Co daje największą szansę obrony |
|---|---|---|---|
| Wolumetryczny | Łącze i przepustowość | Skok transferu, zapchanie pasma, spadek dostępności dla wszystkich | CDN, Anycast, filtracja u dostawcy, szybkie odcięcie źródeł ruchu |
| Protokołowy | Stosy sieciowe i zasoby pośrednie | Dużo krótkich, kosztownych połączeń, problemy z sesjami i stanami połączeń | Rate limiting, ochrona na poziomie sieci, dobrze ustawione limity i firewalle |
| Aplikacyjny | CPU, bazę danych i logikę aplikacji | Na pierwszy rzut oka ruch wygląda "normalnie", ale jedna funkcja dostaje lawinę żądań | WAF, cache, kolejki, kontrola kosztownych endpointów, autoryzacja i limity per użytkownik |
| Wielowektorowy | Kilka warstw naraz | Połączenie zalewu sieciowego z zapytaniami do aplikacji | Obrona warstwowa i dobry runbook, bo jedna reguła nie wystarczy |
Najwięcej problemów robi dziś wariant wielowektorowy, bo zmusza zespół do walki na kilku frontach naraz. Jeśli WAF zatrzyma jedną falę, a warstwa sieciowa nadal jest przeciążona, użytkownik i tak zobaczy awarię. Z tego powodu sama lista narzędzi nie wystarcza; potrzebny jest też plan obserwacji i szybkiej diagnozy, który pozwala odróżnić atak od legalnego wzrostu ruchu.
Po czym poznać, że to nie zwykły skok ruchu
To jeden z najbardziej niedocenianych problemów. W praktyce największa trudność nie polega na tym, że ruch jest duży, tylko na tym, że wygląda wiarygodnie. Premiera produktu, kampania reklamowa, virale w social mediach albo publikacja w dużych mediach potrafią generować objawy łudząco podobne do przeciążenia.
| Sygnał | Co może oznaczać | Na co patrzę najpierw |
|---|---|---|
| Skok 5xx, zwłaszcza 502, 503 i 504 | Upstream, aplikacja albo przeciążony backend | Logi reverse proxy, obciążenie CPU, czas odpowiedzi baz danych |
| Ruch skupiony na jednym endpointcie | Celowanie w kosztowną funkcję | Który URL lub API zbiera większość żądań |
| Nietypowy rozkład geograficzny lub ASN | Rozproszony ruch z wielu źródeł | Wzorce IP, kraje, dostawcy, powtarzalne fingerprinty |
| Wysoki ruch, ale niski współczynnik konwersji i krótki czas sesji | Dużo żądań bez realnej aktywności użytkowników | Ścieżki sesji, nagłówki, cookies, zachowanie w przeglądarce |
| Problemy z DNS albo z kolejką połączeń | Wąskie gardło poza samą aplikacją | Resolver, TTL, limity połączeń, pośrednie urządzenia sieciowe |
Jeśli mam wybrać jedną rzecz do sprawdzenia jako pierwszą, wybieram nie sam wolumen, tylko to, czy ruch skupia się na jednym kosztownym punkcie systemu. Taki obraz najczęściej zdradza, że problem nie jest "większym zainteresowaniem", tylko próbą wyczerpania zasobów. Gdy to wiemy, można sensownie przejść do obrony zamiast zgadywania.
Jak buduję obronę warstwową w praktyce
Najlepsza ochrona nie polega na jednym cudownym narzędziu. Składa się z kilku warstw, które łapią atak na różnych etapach: zanim trafi do originu, zanim wyczerpie sesje i zanim zje zasoby aplikacji. Właśnie tak powinien wyglądać dojrzały model obrony w firmie, która nie chce uczyć się na własnym przestoju.
Ogranicz powierzchnię ataku
Najtańsza obrona to ta, której napastnik w ogóle nie ma jak testować. Publicznie wystawiaj tylko te usługi, które naprawdę muszą być dostępne z internetu. Resztę przenoś za prywatne połączenia, segmentuj sieć, trzymaj panele administracyjne poza głównym ruchem i pilnuj, żeby niepotrzebne porty nie były otwarte "na wszelki wypadek".
Oddziel warstwę sieci od aplikacji
CDN, Anycast i WAF robią ogromną różnicę, bo przesuwają filtrację bliżej źródła ruchu. Cloudowe mechanizmy potrafią też szybciej reagować na anomalie niż lokalna infrastruktura. Microsoft Learn podaje, że w środowisku Azure automatyczna mitigacja dla ochrony sieciowej może uruchamiać się w przedziale 30-60 sekund, co pokazuje, jak ważna jest automatyzacja zamiast ręcznego gaszenia pożaru.
Ustal limity i priorytety
Rate limiting, limity na sesję, limity na IP, ograniczenia kosztownych endpointów i cache dla treści statycznych to nie są drobiazgi. To właśnie one sprawiają, że serwis nie pada po pierwszych minutach wzmożonego ruchu. Ja szczególnie pilnuję dwóch rzeczy: ograniczenia loginów i ochrony funkcji, które generują najdroższe zapytania do bazy albo zewnętrznych API.
Przeczytaj również: Cyberbezpieczeństwo - Co działa w praktyce? Dom i firma
Zrób miejsce na degradację, nie tylko na idealne działanie
System, który albo działa w pełni, albo nie działa wcale, jest zbyt kruchy. Lepiej mieć tryb awaryjny: uproszczony front, odcięte elementy poboczne, kolejkę żądań, statyczną stronę statusową i jasny plan komunikacji. To nie jest porażka produktu, tylko kontrolowane ograniczenie szkód.
Po takiej architekturze następny krok jest już operacyjny: trzeba wiedzieć, co robić, kiedy alarm faktycznie się zapali. Bez tego nawet dobra infrastruktura traci połowę wartości.
Co robić w pierwszych minutach incydentu
W pierwszych minutach liczy się spokój i kolejność działań. Najgorsza decyzja to chaotyczne klikanie reguł bez zrozumienia, czy patrzysz na atak, czy na legalny pik. Dlatego traktuję początek incydentu jak prosty runbook.
- Potwierdź, czy wzrost ruchu nie ma naturalnego źródła, na przykład premiery, kampanii albo publikacji w mediach.
- Włącz alertowanie i poinformuj osoby odpowiedzialne za sieć, aplikację, operacje i komunikację z klientem.
- Przenieś ochronę na tryb awaryjny: ostrzejszy WAF, silniejsze limity, dodatkowe reguły filtrowania, ewentualnie challenge dla podejrzanych żądań.
- Odetnij kosztowne ścieżki, które nie są krytyczne dla podstawowej działalności, i zwiększ cache tam, gdzie to możliwe.
- Chroń origin, bo jego wyczerpanie zwykle oznacza dłuższy przestój niż sama awaria warstwy brzegowej.
- Zapisuj czasy, adresy, metryki i zmiany konfiguracyjne, bo bez tych danych analiza po incydencie jest dużo mniej użyteczna.
Ważna zasada: nie blokuj wszystkiego tylko po to, żeby "na chwilę uciszyć" problem. Jeśli serwis obsługuje klientów, taki ruch może bardziej zaszkodzić niż pomóc. Lepiej zawężać ruch stopniowo i sprawdzać efekt każdej zmiany, niż w ciemno odcinać całe grupy użytkowników. To prowadzi do ostatniego pytania: co z tego wszystkiego naprawdę zostaje po spokojnej stronie zespołu, kiedy minie alarm.
Najmocniejsza ochrona powstaje przed incydentem, nie podczas niego
Jeśli miałbym wskazać jedną rzecz, która robi największą różnicę, powiedziałbym: odporność na przeciążenie buduje się warstwami, zanim pojawi się pierwszy alert. Dobrze ustawiony CDN, WAF, limity, cache, monitoring i gotowy plan reakcji dają więcej niż pojedynczy drogi produkt kupiony po fakcie. W praktyce wygrywają ci, którzy potrafią szybko odróżnić ruch legalny od szkodliwego i mają już przygotowane decyzje, a nie dopiero pytania.
Na końcu zostaje jeszcze jedna rzecz, o której często się zapomina: testy. Warto okresowo symulować wzrost ruchu, sprawdzać zachowanie proxy, DNS, aplikacji i komunikacji statusowej, bo dopiero wtedy widać, gdzie naprawdę leży słabe ogniwo. Jeśli infrastruktura nie wytrzymuje kontrolowanego szumu, prawdopodobnie nie wytrzyma też nieprzewidzianego sukcesu albo prawdziwego ataku.